Andrew Fuchs, Michael Walton, Theresa Chadwick, Doug Lange
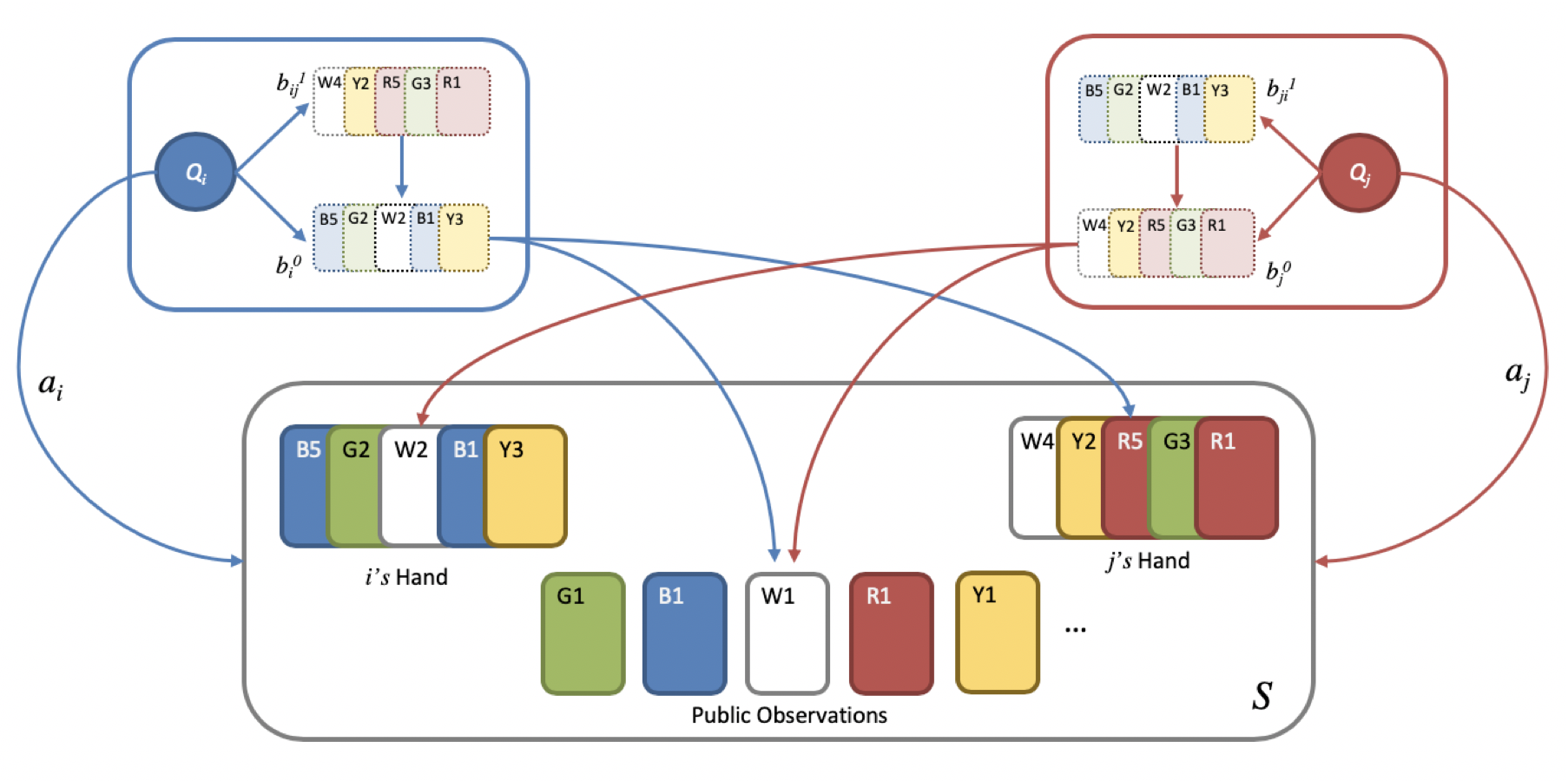 The partially observable card game Hanabi has recently been proposed as a new AI challenge problem due to its dependence on implicit communication conventions and apparent necessity of theory of mind reasoning for efficient play. In this work, we propose a mechanism for imbuing Reinforcement Learning agents with a theory of mind to discover efficient cooperative strategies in Hanabi. The primary contributions of this work are threefold: First, a formal definition of a computationally tractable mechanism for computing hand probabilities in Hanabi. Second, an extension to conventional Deep Reinforcement Learning that introduces reasoning over finitely nested theory of mind belief hierarchies. Finally, an intrinsic reward mechanism enabled by theory of mind that incentivizes agents to share strategically relevant private knowledge with their teammates. We demonstrate the utility of our algorithm against Rainbow, a state-of-the-art Reinforcement Learning agent.
The partially observable card game Hanabi has recently been proposed as a new AI challenge problem due to its dependence on implicit communication conventions and apparent necessity of theory of mind reasoning for efficient play. In this work, we propose a mechanism for imbuing Reinforcement Learning agents with a theory of mind to discover efficient cooperative strategies in Hanabi. The primary contributions of this work are threefold: First, a formal definition of a computationally tractable mechanism for computing hand probabilities in Hanabi. Second, an extension to conventional Deep Reinforcement Learning that introduces reasoning over finitely nested theory of mind belief hierarchies. Finally, an intrinsic reward mechanism enabled by theory of mind that incentivizes agents to share strategically relevant private knowledge with their teammates. We demonstrate the utility of our algorithm against Rainbow, a state-of-the-art Reinforcement Learning agent.